1) 옵티마이저(Optimizer)
- SQL에서의 옵티마이저는 데이터베이스 관리 시스템(DBMS) 내부에 내장된 소프트웨어 구성 요소로, 사용자의 SQL 쿼리를 효과적으로 실행하기 위한 최적의 방법(실행 계획)을 선택하는 역할을 합니다. 쿼리의 성능과 관련된 여러 가지 방법을 고려하여 최적으로 실행 경로를 결정합니다.
- 실행계획(Execution Plan) : 옵티마이저가 생성한 SQL 처리 경로
2) 옵티마이저(Optimizer) 종류
1. 롤 기반 옵티마이저(RBO - Rule-Based Optimizer)
- 이전의 데이터베이스 시스템에서 주로 사용되던 방식입니다.
- 사전 정의된 규칙 세트를 기반으로 실행 계획을 생성합니다.
- 예를 들어, 주어진 쿼리에 인덱스가 사용 가능하면 인덱스를 사용하는 것과 같은 규칙을 가집니다.
- RBO는 현대의 복잡한 데이터 베이스 환경에서는 더 이상 널리 사용되지 않습니다.
2. 비용 기반 옵티마이저(CBO, Cost-Based Optimizer)
- 대부분의 현대적인 DBMS에서 사용하는 옵티마이저입니다.
- 통계 정보(테이블의 행 수, 인덱스의 유일성, 데이터의 분포 등)를 기반으로 여러 가지 가능한 실행 계획 중에서 최소의 비용을 가지는 실행 계획을 선택합니다.
- '비용'은 일반적으로 디스크 I/O, CPU 시간 등의 자원 사용을 나타냅니다.
- CBO를 최적으로 활용하려면 데이터베이스의 통계 정보를 정기적으로 업데이트해야 합니다.
- CBO가 실행계획을 수립할 때 판단 기준이 되는 비용은 어디까지나 예상치이다.
1) 미리 구해놓고 테이블과 인덱스에 대한 여러 통계정보를 기초로 각 오퍼레이션 단계별 예상 비용을 산정하고, 이를 합산한 총비용이 가장 낮은 실행계획을 선택
2) 비용을 산정할 때 사용되는 오브젝트 통계 항목으로는 레코드 개수, 블록 개수, 평균 행 길이, 칼럼 값의 수, 칼럼 값 분포, 인덱스 높이(Height), 클러스터링 팩터 같은 것들이 있음
비용 기반 옵티마이저(CBO)를 사용하는 주요 이유는 쿼리의 성능을 최적화하기 위함입니다. "비용"이라는 용어는 데이터베이스 시스템에서 쿼리를 실행하는 데 필요한 자원(예: 디스크 I/O, CPU 시간)의 양을 나타내며, CBO의 목적은 이 비용을 최소화하는 방식으로 쿼리를 실행하는 것입니다.
레코드 개수, 블록 개수, 평균 행 길이, 칼럼 값의 수, 칼럼 값 분포, 인덱스 높이(Height), 클러스터링 팩터 등은 직접적으로 "자원"이라고 부르기보다는 데이터베이스의 구조와 데이터의 특성을 설명하는 "통계 정보"나 "메타데이터"의 일부로 봐야 합니다.
비용 기반 옵티마이저(CBO)는 이러한 통계 정보를 기반으로 최적의 쿼리 실행 계획을 결정합니다. 이 정보들은 CBO에게 데이터의 분포와 특성, 테이블과 인덱스의 구조에 대한 중요한 단서를 제공하여, 어떤 방식으로 쿼리를 실행할 때 가장 효율적인지를 판단하는 데 도움을 줍니다.
레코드 개수: 테이블의 크기를 나타내며, 전체 테이블 스캔과 인덱스 스캔 중 어떤 것이 더 효율적인지 판단하는 데 도움을 줍니다.
클러스터링 팩터: 인덱스의 효율성을 나타내는 지표로, 인덱스를 사용하여 데이터를 조회할 때의 효율성을 평가하는 데 사용됩니다.
칼럼 값 분포: 칼럼의 값들이 얼마나 고르게 분포되어 있는지를 나타내며, 특정 값을 가진 레코드를 찾을 확률을 추정하는 데 도움을 줍니다.
옵티마이저는 데이터베이스 시스템에서 쿼리 성능에 굉장히 중요한 역할을 합니다.
1. 성능 최적화
- 동일한 결과를 반환하는 여러 쿼리 실행 방법이 있을 수 있습니다. 옵티마이저는 이 중에서 가장 효율적인 방법을 선택하여 자원 사용을 최소화하고 응답 시간을 줄여줍니다.
2. 자원 효율성
- 데이터베이스는 종종 제한된 리소스(CPU, 메모리, 디스크 I/O 등) 내에서 동작합니다. 옵티마이저는 가능한 최적의 방법으로 쿼리를 실행하여 이러한 리소스를 효율적으로 활용합니다.
3. 복잡성 감소
- 사용자나 개발자는 쿼리를 작성할 떄 데이터의 실제 물리적 구조나 저장 방식을 깊게 알 필요가 없습니다. 옵티마이저가 이런 내부적인 세부 사항을 처리하므로, 사용자는 단순히 원하는 결과에 집중할 수 있습니다.
4. 동적 환경 대응
- 데이터의 크기, 분포, 사용 패턴 등은 시간이 지남에 따라 변경될 수 있습니다. 옵티마이저는 이러한 동적 환경 변화에 유연하게 대응하며, 최적의 실행 계획을 동적으로 선택할 수 있습니다.
5. 고도화된 기능 제공
- 현대의 데이터베이스 관리 시스템은 다양한 고급 기능(파티셔닝, 병렬 처리, 인덱스 최적화 등)을 제공합니다. 옵티마이저는 이러한 기능들을 통합적으로 고려하여 최적의 쿼리 실행 계획으르 생성합니다.
결과적으로, 옵티마이저는 데이터베이스 성능을 최대화하고, 자원 사용을 최적화하며, 사용자와 개발자에게 복잡한 내부 작업을 숨기는 중요한 역할을 합니다. 따라서 데이터베이스 관리나 성능 최적화에 있어서 옵티마이저의 역할과 중요성은 강조되곤 합니다.
3) 옵티마이저(Optimizer) 최적화 과정

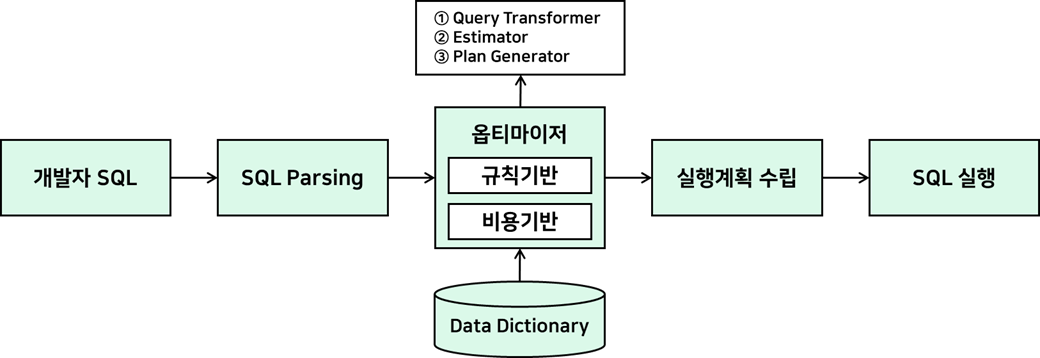
| 1. SQL 실행 | 2. 파싱(Parsing) | 3. 실행계획 수립 | 4. 실행계획 저장 | 5. SQL 실행 및 인출 |
| 개발자가 SQL문을 작성하고 실행함 | SQL의 문법검사 및 구문분석 수행 | 옵티마이저가 SQL 실행계획 수립 | 실행계획 수립 및 선정 완료 휴 저장함 | SQL 실행 및 데이터 인출(Fetch) |
1. 실행 계획 후보군 생성 : 사용자가 제출한 SQL 쿼리를 실행하는 데 가능한 여러가지 방법(실행 계획)을 생성합니다. 이때, 여러 가지 테이블 스캔 방식, 조인 순서, 조인 방식, 인덱스 사용 여부 등을 고려합니다.
2. 통계 정보 활용 : Data Dictionary에 저장된 오브젝트 통계(예 : 테이블 크기 , 칼럼 분포, 인덱스 정보 등)와 시스템 통계(예: I/O 비용, CPU 비용 등)를 사용하여 각 실행 계획의 예상 비용을 계산합니다.
3. 최적에 실행 계획 선택 : 각 실행 계획의 예상 비용을 비교하여 가장 낮은 비용을 갖는 실행 계획을 선택합니다.
선택된 실행 계획은 데이터베이스 엔진에 의해 실행되며, 결과적으로 사용자의 쿼리에 대한 겨로가가 반환됩니다.
이러한 과정은 데이터베이스의 성능을 최적화하기 위해 설계된 것이며, 비용 기반 옵티마이저의 핵심 원리와 동작 방식을 잘 반영하고 있습니다.
- Parser : SQL문장을 이루는 개별 구성요소를 분석하고 파싱해서 파싱 트리를 만든다.( Syntax(문법), Semantic(의미) )
- Query Transformer : 파싱된 SQL을 좀 더 일반적이고 표준적인 형태로 변환한다.
- Estimator : 오브젝트 및 시스템 통계정보를 이용해 쿼리 수행 각 단계의 선택도, 카디널리티, 비용을 계산하고, 궁극적으로는
실행계획 전체에 대한 총비용을 계산해 낸다. - Plan Generator : 하나의 쿼리를 수행하는데 있어, 후보군이 될만한 실행계획들을 생성해 낸다.
- Row-Source Generator : 옵티마이저가 생성한 실행계획을 SQL 엔진이 실제 실행할 수 있는 코드(또는 프로시저 ) 형태로 포맷팅한다.
- SQL Engine : SQL을 실행한다.
3) 옵티마이저(Optimizer) 예시
규칙 기반 옵티마이저(RBO) 예시
RBO는 정해진 규칙 목록을 기반으로 실행 계획을 선택합니다.
1. WHERE 절에서의 등호(=)조건이 있는 칼럼에 인덱스가 있으면 이덱스 스캔을 사용한다.
2. 없으면 테이블 전체 스캔을 한다.
SELECT * FROM employees WHERE employee_id = 123;
만약 'employee_id' 칼럼에 인덱스가 있다면, RBO는 첫 번째 규칙을 따라 인덱스 스캔을 선택할 것입니다. 인덱스가 없다면 테이블 전체 스캔을 선택할 것입니다.
비용 기반 옵티마이저(CBO) 예시
CBO는 데이터베이스 통계와 예상 작업 비용을 기반으로 최적의 실행 계획을 선택합니다.
SELECT * FROM employees WHERE employee_id = 123;CBO는 'employees' 테이블의 크기, 'employee_id' 칼럼의 값 분포, 인덱스이 통계 정보 등을 고려하여 예상 비용을 계산합니다. 예를 들어 'employees'테이블이 매우 작으면, 인덱스 스캔의 비용과 테이블 전체 스캔의 비용이 거의 비슷할 수 있습니다. 따라서 CBO는 이러한 통계와 예상 비용을 바탕으로 최적의 실행 계획을 선택하게 됩니다.
이 두 예시를 통해 볼 때, RBO는 고정된 규칙에 따라 실행 계획을 결정하는 반면, CBO는 실제 데이터의 특성과 분포를 기반으로 최적의 실행 계획을 동적으로 선택하는 것을 알 수 있습니다.
RBO는 예측 가능하고 일관된 성능을 제공하는 반면, CBO는 다양한 상황에서 최적의 성능을 제공하는 유연성을 가집니다. 현대의 데이터베이스 환경에서는 데이터의 크기와 복잡도가 끊임없이 변화하므로, CBO의 동적인 최적화 방식이 더욱 효과적인 경우가 많습니다.